What is LLM Observability & Monitoring?
Building reliable LLM-based applications in production is incredibly challenging. You’ve probably heard of the term LLM Observability. But what exactly is it? How does it differ from traditional observability? And why is it crucial for your AI applications? Let’s dive in.

Introduction
The introduction of Large Language Models (LLMs) like GPT has transformed application development, enabling more natural and sophisticated language understanding and generation. Deploying these models in production, however, introduces complexities that traditional observability tools cannot address. LLM Observability has become essential to ensure the reliability, performance, and security of AI-powered applications.
What is LLM Observability?
LLM Observability refers to the comprehensive monitoring, tracing, and analysis of applications that leverage Large Language Models. It involves gaining deep insights into every aspect of the system, from the intricacies of prompt engineering and model responses to user interactions and overall application performance.
By implementing LLM observability, developers and engineers can:
- Understand Model Behavior: Gain visibility into how the model processes inputs and generates outputs.
- Diagnose Issues: Quickly identify and resolve errors, bottlenecks, and anomalies.
- Optimize Performance: Enhance latency and throughput by fine-tuning model parameters and infrastructure.
- Enhance User Experience: Tailor responses to meet user expectations and improve satisfaction.
- Ensure Compliance: Maintain data privacy and adhere to regulatory requirements.
The Need for LLM Observability
LLM Observability vs. Traditional Observability
Let’s compare traditional observability with LLM observability to highlight the critical differences:
| Aspect | Traditional Observability | LLM Observability |
|---|---|---|
| Data Types | System logs, performance metrics | Model inputs/outputs, prompts, embeddings |
| Predictability | Deterministic systems with expected behaviors | Non-deterministic models with variable outputs |
| Interaction Scope | Single requests/responses | Complex conversations, including context over time |
| Evaluation | Error rates, exceptions, latency | Response quality, user satisfaction, ethical considerations |
| Tooling | APMs, log aggregators, monitoring dashboards | Specialized tools for model monitoring and prompt analysis |
Key Components of LLM Observability
1. Prompt and Response Logging
At the core of LLM observability is the detailed logging of prompts and their corresponding responses. Recording these interactions allows for analysis of patterns and understanding how context influences outputs. Maintaining conversation histories provides insight into the model’s behavior over time, while using standardized prompt templates enhances consistency across interactions.
2. Performance Monitoring and Tracing
Monitoring the performance of your LLM applications ensures a smooth user experience. Tracking latency helps identify any delays in response generation, and capturing errors such as API failures or exceptions within the model pipeline is crucial for reliability. Tracing user interactions provides a deeper understanding of how inputs are transformed into outputs.
3. Quality Evaluation Metrics
Assessing the quality of the model’s outputs is vital for continuous improvement. Defining clear metrics—such as relevance, coherence, and correctness—enables monitoring of how well the model meets user expectations. Collecting feedback directly from users offers valuable insights, while automated evaluation methods provide consistent assessments when human evaluation isn’t practical.
4. Anomaly Detection and Feedback Loops
Detecting anomalies, like unusual model behaviors or outputs indicating hallucinations or biases, is essential for maintaining application integrity. Implementing mechanisms to scan for inappropriate or non-compliant content helps prevent ethical issues. Feedback loops, where users can provide input on responses, facilitate iterative improvement over time.
5. Security and Compliance
Ensuring the security of your LLM application involves implementing strict access controls to regulate who can interact with model inputs and outputs. Protecting sensitive data requires compliance with regulations like GDPR or HIPAA. Maintaining detailed audit trails promotes accountability and aids in meeting compliance requirements, building user trust.
Common Challenges in LLM Applications
Deploying LLMs in production comes with its set of challenges. Here’s how you can address them and how Helicone can assist.
Hallucinations 🧠
LLMs may generate outputs that sound plausible but are factually incorrect or nonsensical—a phenomenon known as hallucination. This undermines user trust and can lead to misinformation.
Mitigation Strategies:
- Prompt Refinement: Design prompts that encourage accurate outputs.
- User Feedback: Collect and incorporate user feedback to correct inaccuracies.
How Helicone Helps: Helicone offers prompt management tools and user feedback features to help refine prompts and improve model outputs. Learn more in our Prompt Management documentation.
Prompt Injection and Security Risks 🔒
Malicious users might manipulate inputs to trick the model into revealing sensitive information or performing unintended actions.
Mitigation Strategies:
- Input Validation: Implement strict validation of user inputs.
- Output Filtering: Block inappropriate or malicious responses.
How Helicone Helps: Helicone provides advanced security features that detect and prevent prompt injection attacks, safeguarding your application from malicious exploits. Learn more in our LLM Security documentation.
Performance and Latency ⚡
High computational demands of LLMs can lead to increased latency and affect the time to first token (TTFT), impacting user experience.
Mitigation Strategies:
- Latency Monitoring: Track latency and TTFT metrics across models.
- Model Comparison: Evaluate models side by side to select the most efficient one.
- Fallback Solutions: Implement fallbacks to ensure availability during downtime.
How Helicone Helps: Helicone lets you compare models and providers using prompt experiments to optimize latency. For availability, Helicone offers Gateway Fallbacks to automatically switch to backup providers.
Cost Management 💰
Ensuring profitability is a challenge as the cost of LLM usage can be high.
Mitigation Strategies:
- Cost Tracking: Monitor LLM costs per project or user to understand spending.
- Efficient Resource Allocation: Optimize infrastructure and usage.
- Model Optimization: Fine-tune smaller, open-source models to reduce costs.
How Helicone Helps: Helicone provides detailed cost analytics, allowing you to segment and track costs over time to ensure profitability. Learn more in our Cost Calculation documentation.
Ethical and Compliance Concerns 🏛️
LLMs may produce biased, offensive, or non-compliant content, leading to reputational damage and legal issues.
Mitigation Strategies:
- Bias Monitoring: Assess outputs for biased or inappropriate content regularly.
- Policy Enforcement: Ensure adherence to ethical guidelines and regulations.
How Helicone Helps: Helicone offers LLM Security features and moderation tools to detect and prevent inappropriate outputs. Learn more in our LLM Security and Moderations documentation.
Conclusion
The deployment of Large Language Models brings immense potential but also significant complexity. Traditional observability methods are insufficient for the nuanced demands of LLMs. By embracing LLM Observability, you gain the insights necessary to build reliable, efficient, and secure AI applications.
At Helicone, we’re committed to supporting you on this journey. Our solutions are tailored to address the specific needs of LLM applications, empowering you to focus on innovation rather than infrastructure.
About Helicone
Helicone is at the forefront of AI observability solutions. Our mission is to simplify the complexities of deploying and managing LLMs in production environments. We provide the tools and expertise to help your organization harness the full potential of AI while maintaining control and oversight.
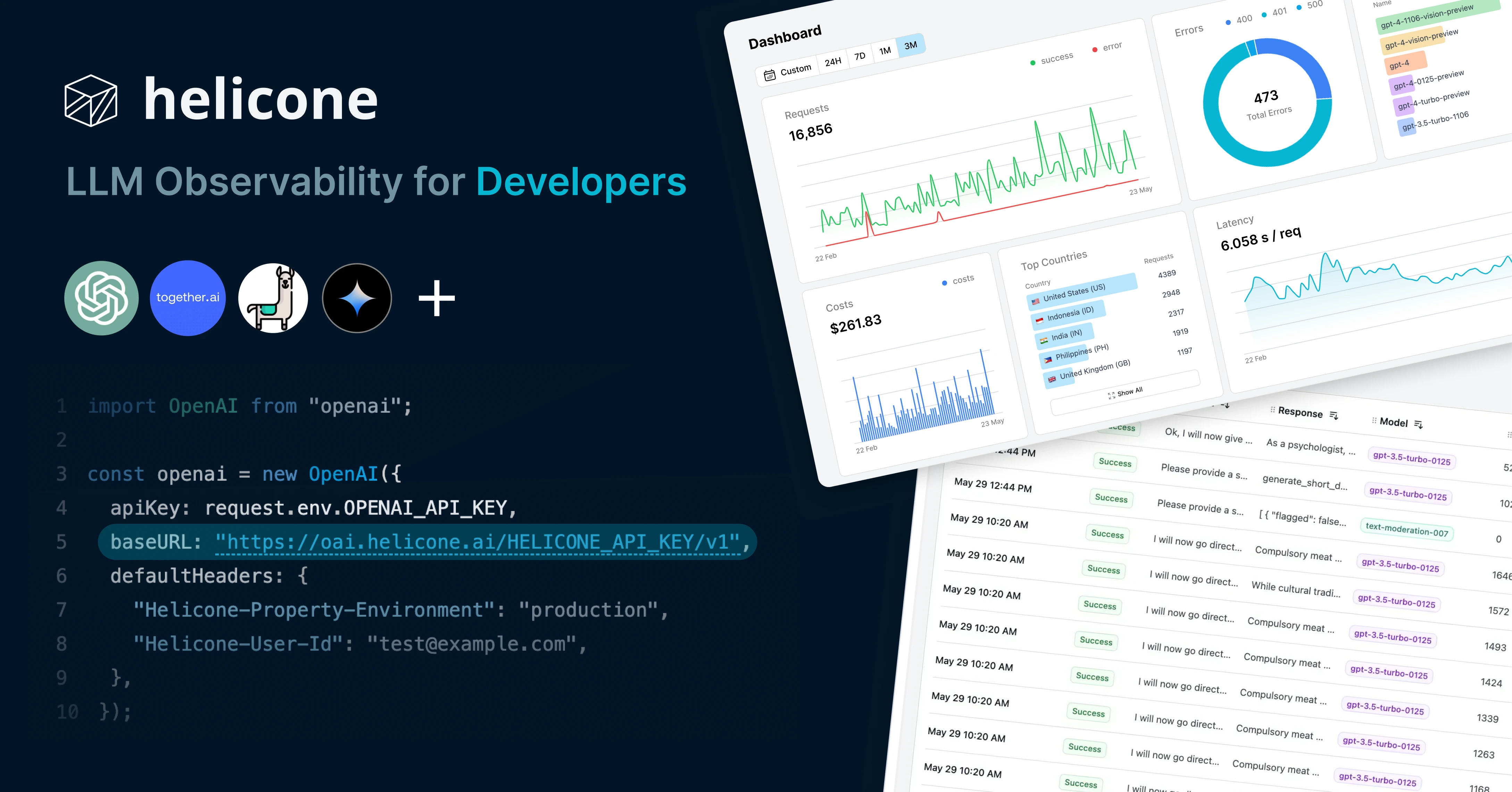
👉 Click here to get started with Helicone today